I assume that most security testers agree that during a web application security testing (black box case), not all pages are found and there is always a potential that something would be missed, in both manual and automated testing. However, I think it is important to highlight strategies and techniques which can be used to decrease chances that things go unnoticed or missing during a security review.
Below, you will find some unusual techniques which I have found useful and which are not automatically implemented in most of the spider/crawler engines I normally use. Such techniques require some manual setup and allowed me to discover additional content and information about the applications I was testing. These techniques are not always applicable or effective, but the underlying logic might be reused in many cases or might hopefully give you new ideas on how to approach a more comprehensive spidering.
| Technique: Add bogus basic authentication header |
| Description: Add bogus basic authentication header with dummy credentials (e.g. test:test) to each HTTP request performed. Ideally, this should be done in parallel or after a standard spidering. |
| Standard Request: GET / HTTP/1.1 Host: example.net Response: 200 OK Same request, but additional basic auth header: GET / HTTP/1.1 Host: example.net Authorization: Basic dGVzdDp0ZXN0 Response: 401 Authorization Required |
| Experience: I have found this technique useful as in few cases it triggered 401 responses from the web server. This might be useful for identifying parts of the application which require authentication or where brute-force password attacks are possible. It is important to notice that such login was not identified during the standard spidering and it would have gone unnoticed. The cause of this behaviour was due to an incorrect configuration on a particular web server instance that I was testing. |
| Technique: Spider web site simulating an old browser / client |
| Description: Spider a web site simulating an old browser or client. This implies that the request should not conform to RFC directives and should be malformed. In few words, the spider should simulate an old browser to get interesting reactions from the web server or other components, such as load balancers or web proxies. |
| In the example below, the Host: header is missing, that would not conform with the HTTP/1.1 RFC 2616 and would be interpreted by most web servers as a malformed request. In case of Apache, the server will return the default page for the first virtualhost configured (if virtual hosts are enabled). Request sent to domain example.com GET / HTTP/1. Host: example.com Host: Response: HTTP/1.1 301 Moved Permanently [...] The document has moved <a href="http://admin.example.net">here</a>. [...] |
| Experience: Some web servers like Apache (and also Nginx) might reveal extra information, such as the domain name of the first virtualhost for backward compatibility, as seen above. This can be useful especially when dealing with large web application testing and need of information gathering. Leaking of additional virtual hosts name means that the web server might have more than one virtual host configured at the same IP address and therefore multiple domain names might resolve to the same IP address. In my case, the virtualhost returned a subdomain name which would have taken different hours to guess with a standard DNS domain name brute-force attack. |
| Technique: Use extra Headers to support CORS |
| Description: Use extra Headers to support CORS. Use OPTIONS verb for each request. |
| Example: GET / HTTP/1.1 [...] Origin: http://mysite.com [...] Response: [...] Access-Control-Allow-Origin: http://mysite.com Access-Control-Allow-Credentials: true [...] In this case, it is possible to ascertain there is a correlation between example.com and mysite.com. Furthermore, the server indicates that credentials can be sent through. |
| Experience: I have found the use of appending Origin: header useful in one case where a web site was providing a JSON service which could only be used from a determined "origin". By inferring the origin domain from the JavaScript code, I have found that the same domain was also allowed in a different part of the application, discovering a further JSON service end-point that the spider did not find in the first place. |
| Technique: Traverse using custom HTTP Request Headers |
| Experience: The application included a Java Applet which would make a request using a custom HTTP request header (e.g. Foo: bar). Later, I found out that the same header was used in a routing decision by the application and lead to reach a part of the application which was not found during spidering. Reuse of gathered information, as in the previous case, can be useful and it is important to re-spider the web site content with the acquired information. |
| Technique:Traverse site using both HTTP/1.0 and HTTP/1.1 |
| Description: Traverse site using both HTTP/1.0 and HTTP/1.1 and observe differences in responses. Use of HTTP 1.0 might lead the web server to react in a different way than by receiving an HTTP/1.1 instead. Some web servers can be configured to not provide certain content or pages to older client and might redirect those clients to other pages. |
| Experience: This technique was useful only in a single case where the application provided a different section when issuing a request with HTTP/1.0 and an old User-Agent version MSIE 4. |
| Description: In some applications, the User-Agent header is used to return certain pages. For example, iPhone or Android users might get redirected to a section of the site which is only supposed to be used by mobile handset users. The same behaviour can be observed for a search engine crawler/robot. Use of a spider bot, such as Googlebot/2.1 might reveal parts of an application which needs to be indexed in search engine results pages but should not be available to a standard user using a browser. Also, it is known that certain application performs cloaking based on User-Agent. A useful resource which provides a comprehensive listing of user agents can be found here. |
| Experience: A colleague (Andrew Horton) remembered me about this technique and I forgot to add it in this list. This technique was useful to me in an instance where I have found a separate part of the application which provided further functionality to mobile users. Interestingly enough, that part of the application had more relaxed security controls than the ones deployed to the main application. Probably, this derives from a false sense of security given by the assumption that browsers would not use that part of the application. |
![]() Setting tools
Setting tools
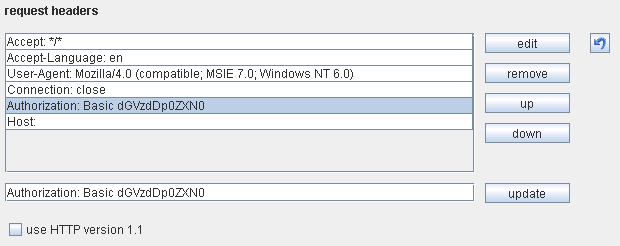
If Burp Proxy is used along with its spidering engine, some manual configuration is required. Under Spider options, it is possible to add custom HTTP headers and to tick/un-tick "Use of HTTP Version 1.1". Modifying the default Spider settings will be sufficient to spider a web site following the above techniques. This is shown in the screen shot below:
Changing Burp - Spider Options
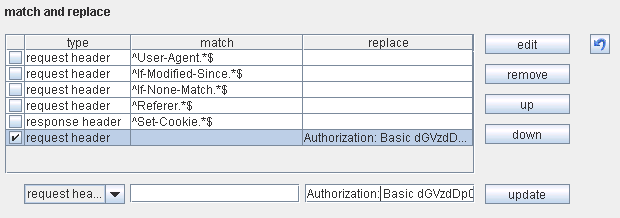
If a tool is required to go through a proxy, then Burp Proxy can be configured under the Proxy Settings. In this case, it is not possible to add, but instead, use "Match and Replace" and then just insert the custom HTTP header under the Replace tab, as shown below.
Changing Burp - Proxy Options
Some tools allow setting custom HTTP Headers and other elements, such as Cookie through the command line. For example, in skipfish, the flag -C name=val sets a cookie and the flag -H name=val sets a custom HTTP header.
The downside of this approach is that if you want to apply more than a single technique against the same target application, you might need to run several spidering/scanning sessions and then merge, update and centralise the results. Also, some tools do not support all mentioned techniques and it might be required to run those tools through a proxy several times.
One partial solution for this problem is to have multiple instances of Burp Proxy configured in a chain of proxies. The "last" proxy in the chain will act as a central point and all the requests would go through it, although some inconsistencies might be faced.
For example, one of the issues that I find relates the way HTTP requests/responses are shown in the proxy. Consider two spider engines (A and B). They both spider the same page using different techniques and use Burp Proxy. The server returns 200 OK in both cases, but different content. Note that Spider A requests the same page before than Spider B does. If Burp Proxy is used with the "Target" feature, only the first request/response will be visible under the Target tab. In this case, only the request/response of Spider A will be shown, something which can be misleading, especially if Spider B found something interesting.
Conclusion
In conclusion, with the planned OWASP Testing Guide v4, these and other techniques for better spidering should be included to improuve the current reconnaissance phase in the methodology. Ideally, also some web scanner/spiders should implement a similar logic and provide the possibility to run more advanced and complex spidering modules.
![]() -
permalink -
-
permalink - ![]()